Распознавание образов мобильным роботом.
Задача распознавания образов
Данная статья посвещена проблеме технического зрения и распознавания образов мобильным роботом. Упор делается не на высокую научность, а на практическое применение, т.е. все описанное ниже работает на реальном мобильном роботе.Постановка задачи: Мобильный робот по ходу движения должен распознавать образы-команды, изображенные на полу, при помощи видеокамеры. С малым числом образов задача должна решаться в реальном времени. Алгоритм распознавания должен быть инвариантен относительно размера образов и их положения (поворота). Все работает под ОС Windows.
Поскольку основная программа управления роботом была написана на Delphi7, то и модуль распознавания пришлось реализовать на Delphi. Любителям C++ Builder рекомендую посмотреть описание программы распознавания образов на C++ использующую подобный алгоритм.
Алгоритмы распознавания образов
Теория технического зрения существует не первый день, по этому в литературе можно найти достаточно подходов и решений. Для начала перечислю некоторые из них:1 Алгоритм скелетизации.
В кратце, это некий метод распознавания одинарных бинарных образов, основанный на построение скелетов этих образов и выделения из скелетов ребер и узлов. Далее по соотношению ребер, их числу и числу узлов строится таблица соответствия образам. Так, например, скелетом круга будет один узел, скелетом буквы П - три ребра и два узла, причем ребра относятся как 2:2:1. В программировании данный метод имеет несколько возможных реализаций, подробнее информацию по методу скелетезации можно найти ниже в разделе ссылки.
2 Нейросетевые структуры.
Направление было очень модным в 60е-70е годы, в последствии интерес к ним немного поубавился, т.к солидное число нейронов требует солидные вычислительные мощности, которые обычно отсутствуют на простеньких мобильных платформах. Однако надо иметь ввиду, что нейросети иногда дают весьма интересные результаты, засчет своей нелинейной структуры, более того некоторые нейросети способны распознавать образы инвариантные относительно поворота без какой либо внешней предобработки. Так например сети на основе неокогнейтронов способны выделять некоторые характерные черты образов, и распознавать их как бы образы не были повернуты. Подробнее про эти структуры можено узнать в разделе ссылки.
3 Инвариантрые числа.
Из геометрии образов можно выделить некоторые числа, инвариантные относительно размера и поворота образов, далее можно составить таблицу соответствия этих чисел конкретному образу(почти как в алгоритме скелетезации). Примеры инвариантных числе - число эллера, экцентриситет, ориентация(в смысле расположения главной оси инерции относительно чего-нить тоже инвариантного). Некоторую информацию и мат. часть можно найти в разделе ссылки ниже.
4 Поточечное процентное сравнение с эталоном.
Здесь должна быть некотороя предобработка, для получения инвариантности относительно размера и положения, затем осуществляется сравнение с заготовленной базой эталонов изображений - если совпадение больше чем какая-то отметка, то считаем образ распознанным.
Практическая часть распознавания образов
Три дня проведенные в интернете не дали ничего готового(а жаль), поэтому проанализировав все возможные алгоритмы распознавания я решил пойти по следующему пути и создать систму, которая будет отвечать всем требованиям ТЗ выше.
Надо сказать, что к началу этой работы я уже имел некоторый опыт общения с видеокамерами, и риалтаймовой обработкой. Проанализировав все алгоритмы распознавания, описанные выше, мне показалось, что:
В любом случае каким путем пойти (растровым типа моего, или векторным типа скелетезации) - тут кому что ближе. Изначально я даже хотел воплотить скелетезацию в этой же программе, для того же диплома, только в итоге так намаялся с сетями и доведением всего прочего до ума, что решил - пусть скелеты рисует кто-нить другой :-).
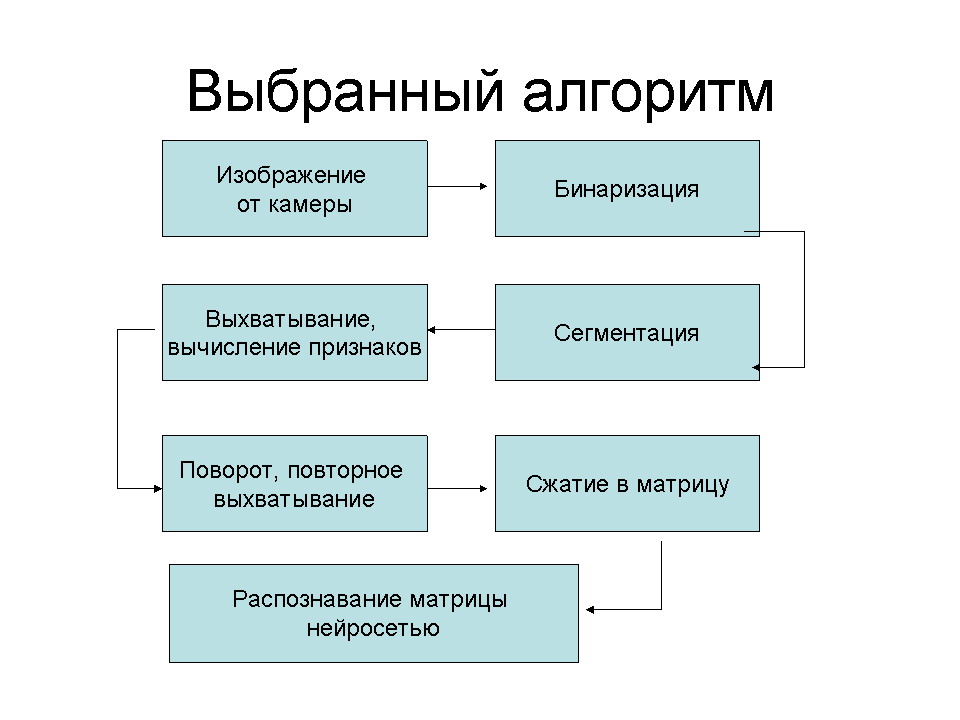
Далее будет описан каждый квадратик этого плана подробно:
Получение изображения с камеры в ОС Windows
Итак для начала нам нужна картинка, с которой потом можно работать. В ОС Windows все источники видео имеют один шаблон. Сам я научиля работать с видео с помощью бесплатных исходников DScap, которые гуляют по англо-инету. Впоследствии, один товарищ из нашей команды основательно распотрошил эти исходники и, подумав, собрал заного - в силу чего ушло много лишнего, появилось много полезного, как например возможность работы с несколькими видео камерами. Не буду описывать происходящее там, ровно как и в соответствующей части моей программы, скажу только: Есть устройство, которое может давать видеопоток (последовательность Bitmap) далее его нужно настроить, для этого запросить драйвер о всех возможных диалогах, которые он (драйвер устройства) может дать. Далее руками в приложении нащелкать нужные настройки (яркость, разрешение дают щелкать все устройства, в некоторых есть число каналов, всякие фильтры и т.п). Затем установить число кадров в секунду - как правило тоже задается. И собственно по событию захвата кадра (драйвером если угодно) будет вызываться ф-ция пользователя, на вход идет кто ее вызвал и еще параметр, собственно захваченный Bitmap в указанной палитре и с указанной яркостью и т.п.
Еще стоит упомянуть про некий альтернативный метод общения с камерой: как я понял, когда только начал капаться, захват так же возможен через API, т.е нужно слать что-то в камеру, а она что-то будет отвечать. Но это, как мне показалось, много сложнее, нежели готовый DirectX.
Скачать демо для работы с видео в Windows под Delphi можно в разделе ссылки ниже.

Бинаризация
В данной программе распознаются только бинарные образы, поэтому вторым этапом после получения картинки, она бинаризуется. При работе с цветной камерой преобразование из цвета в ЧБ идет по стандартной формуле
Y:=0.3*R+0.59*G+0.11*B
Далее алгоритм довольно прост: есть некоторая планка, если цвет оттенка серого выше - он считается белым, если ниже - считается черным. Как видно бинаризация очень проста, однако для серьезного улучшения качества работы распознавания, и уменьшения времени работы последующих модулей, на этом месте лучше ввести некий фильтр, пускай даже самый простенький. Из своей практики могу сказать, что для работы с видео одним из самых простых фильтров являтеся фильтр по контрастности. В своей программе я не использовал такую конструкцию, однако место где она может быть включена обозначено, и на том месте находится более простая приблуда, отслеживающая количество пикселей(белых или черных) идущих подряд, и исключающих возникновение последовательности в ряду : 01010101 .
В режиме дебага места смены цвета, зафиксированные программой можно увидеть по красному обрамлению образов, которое рисуется непосредственно в модуле бинаризации.
Очень важно знать, что стандартные модули DELPHI опроса цвета пикселей в bitmap - вещь ужасно медленная. При ее использовании ни о каком реальном времени говорить не приходится. Для ускорения процесса я использовал внешние бесплатные модули Qpixels, их можно скачать в разделе ссылки. После однократного опроса цветов и их бинаризации, программа работает только с обычной бинарной матрицей(динамическим двумерным массивом), посему далее идет уже все быстро.

Сегментация
Все описанные выше алгоритмы распознавания образов работают с единственным видимым образом, в реальной жизни видеокамера(направленная на пол) может видеть сразу несколько объектов, специально расположенных рядом, или же в поле зрения может попаться какой-нить посторонний объект (нога человека, грязь, потертось пола и прочие приходящие вещи). Если не предусматривать некоторое разбиение общего изображения на части, то ни один из описанных выше алгоритмов не сможет коректно работать. Итак разбиение изображения на части, каждая из которых содержит свой уникальных объект называется сегментацией(см поясняющую илюстрацию ниже :-).

Как и в самом распознавании - в сегментации, за время существования науки, было напридумавано уже достаточно алгоритмов, каждый из которых обладает своими достоинствами, и применяется под конкретную задачу. Для начала замечу еще раз, что в моей задачке идет работа только с черно-белым изображением. Под цвет существуют совершенно иные методы сегментации, нежели будут описаны ниже.
Так же следует заметить, что в сегментации четко разделются черно-белые изображения на бинарные и с оттенками серого. Здесть тоже работают совершенно разные по быстроте и сложности алгоритмы, однако интуетивно понятно, что любое изображение с оттенками серого можно бинаризовать по некоторым правилам.
В моей задаче с камеры поступает пускай и черно-белая, но вполне реальная картинка с 8битной палитрой (цвет задается от 0 до 255), однако для простоты в своем алгоритме я сразуже бинаризирую ее.
Итак, некоторые пояснения.
Как уже было сказано, большинство камер, граберов и прочих устройств в ОС Windows кодирует цвета пикселев в 24битовом формате. Поскольку я работаю в основном с ЧБ камерами, то у них содержимое всех трех 8 битов RGB одинаковое. Мы имеем некоторое изображение, каждый цветов которого изменяется от 0 до 255.
На стадии бинаризации мы должны преобразовать объект изображения в бинарную матрицу данных.
Итак, с этого момента для ускорения процесса начинается работа уже не с объектом картинки, а с бинарной матрицей, образы в которой выглядят примерно так:
00000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000
00000000000001110000111000000000000000000000000000000
00000000000011100001110000000000000011100000000000000
00000000000111000111000000000000000111100000000000000
00000000001110001110000000000000001111100000000000000
00000000011110111000000000000000011001100000000000000
00000000111111100000000000000000110001100000000000000
00000001110011000000000000000000000001100000000000000
00000011100111000000000000000000000001100000000000000
00000111000110000000000000000000000001100000000000000
00001110001110000000000000000000000001100000000000000
00011100001111100000000000000000000001100000000000000
00000000000000000000000000000000000001100000000000000
00000000000000000000000000000000000001100000000000000
00000000000000000000000000000000000001100000000000000
00000000000000000000000000000000000111110000000000000
00000000000000000000000000000000000111110000000000000
00000000000000000000000000000000000000000000000000000
Пример матрицы взят автором не из реальной жизни, а напечан из головы. В реальной жизни в строчке 640 элементов 0 или 1 (по числу пикселей с изображения камеры). Иногда при исползовании точных камер с разрешением 1024х768 размер матрицы будет пропорционально больше. Посему печатать на страничке реальные данные весьма трудно, онднако ниже я буду давать ссылки на фаилы из реального дебага программы.
Следующим пунктом алгоритма должна быть сегментация. Она осуществляется Путем прохода по матрице изображения слева направо, сверху вниз. При проходе выполняются следующие правила:

Итак некоторые коментрарии по правилам: L и M это метки, которые после прохождения алгоритма по массиву(кстати однократного) должны быть присовоены ВСЕМ пикселям объекта (элементам матрицы, которые до сегментации были единичными).
Далее если уже меченные объекты сливаются, то должно происходить и слияние меток.
На бумажке это все выглядит довольно просто, но если подумать то становится ясно, что для коректной работы алгоритма требуется переназначать метки во ВСЕЙ МАТРИЦЕ изображения каждый раз, когда выполняется последнее правило. Как я уже говорил ранее, одна из задач алгоритма это постараться уложиться в реально время, посему проходить по массиву элементов 640х480 каждый раз, когда хочется переназначить метку - это непозволительная роскошь.
Первое что приходит, на ум, чтобы рацианализировать эту часть алгоритма, это завести отдельно массив меток, в котором надо прописывать какая метка на какую ссылается, и все операции при проходе по матрице изображения проводить только с массивом ссылок меток. При этом в конце прохода должен иметься массив меток, ссылающихся друг на друга, и только несколько меток должны быть уникальнымии - которые собственно и образую объекты. Что бы получить уникальные объекты, которые уже можно направить в модуль распознавания нужно всего лишь нормализовать этот массив ссылок и переназначить все элементы матрицы на уникальные метки исходя из данных нормализованного массива ссылок.
На практике такой подход оказался нерабочим: на сложных объектах (что-нить типа горизонтальной плоской змейки) происходило разделение цельного объекта на части, причем в процессе переприсвоения меток терялась связь между частями объекта.
Более правильным, и не сложным решением явилось рекурентное нахождения уникальных родителей каждой метки, и далее всю работу по переприсвоению производить уже с ними, таким образом связь в объекте не может быть потеряна, потому что рекурсия дает возможность выхватывать самые длинные отростки объекта.
Термин отростки явно не будет понятен читателю, который знакомится с материалом первый раз, посему поясняю: на картинке выше (там где буква К и 1ка) стенки у 1ки иделально ровные, на практике же, разрешение 640х480 у камеры, направленной на пол, дает довольно приличную детализацию, которая может выхватывать реальные или кажущуюеся камере "заусенцы" или помехи на ровных местах образа (пускай даже распечатанного на принтере). Врезультате алгоритм работает не с идеальными картинками, а довольно сложными, но это происходит только на стадии сегментации, затем эти лишние детали на больших объектах уйдут, как будет понятно позже.
Итак после выполнения алгоритма сегментации, исходная бинарная матрица элементов должна выглядеть примерно так:
00000000000000000000000000000000000000000000000000000
00000000000000000000000000000000000000000000000000000
00000000000002220000222000000000000000000000000000000
00000000000022200002220000000000000055500000000000000
00000000000222000222000000000000000555500000000000000
00000000002220002220000000000000005555500000000000000
00000000022220222000000000000000055005500000000000000
00000000222222200000000000000000550005500000000000000
00000002220022000000000000000000000005500000000000000
00000022200222000000000000000000000005500000000000000
00000222000220000000000000000000000005500000000000000
00002220002220000000000000000000000005500000000000000
00022200002222200000000000000000000005500000000000000
00000000000000000000000000000000000005500000000000000
00000000000000000000000000000000000005500000000000000
00000000000000000000000000000000000005500000000000000
00000000000000000000000000000000000555550000000000000
00000000000000000000000000000000000555550000000000000
00000000000000000000000000000000000000000000000000000
На картинке выше я специально присвоил "1" метку с номером 5, в реальности элементы которые видит камера довольно сложны, и не идеальны, поэтому при проходе только лишь по началу первого элемента могут быть задействованы несколько номеров меток, таким образом первое число, которое будет образвывать уникальный (в будущем ) объект типа "1" может быть не 3, не 4 , и даже не в первом десятке - у меня это число 5.
Так же на этом этапе даю возможность ознакомится с выходом программы, в реальных увловиях эксплуатации. Здесь можно посмотреть пример как будет происходить сегментация распечатанных на бумаге букв "П" и "И" подсунутых под камеру. Ниже выведен массив меток, про который уже шел разговор. В распечатке массива третий столбик это площадь кусков-сегментов. Ее довольно просто собрать на этом этапе работы программы, затем данные о площади можно использовать в простейшем фильтре, и не пускать мелкий мусор в модуль распознавания.
Пример этот - это реальный выход программы в текстовый фаил, поскольку некоторые метки при проведении сегментации стали двузначными, то картинка немного поползла, что затрудняет ее восприятие, однако при некоторой фантазии и желании можно понять что происходит.
Выхватывание образа, вычисление некоторых инвариантных чисел
После успешного завершения сегментации, каждый сегмент попадает в модуль распознавания (в качестве параметра распознавания в моей программе как раз и идет уникальная метка сегмента).
Надо заметить что еще в модуле сегментации, при финальном проходе по массиву, с переприсвоением меток, для каждого образа обозначаются его границы и вычисляется финальная площадь. Границы нужны для ускорения работы модуля распознавания - т.к он ищет образ только в указанном месте.
Для того, что бы образы распознавались инвариантно относительно положения и поворота надо привязаться к их структуре(форме в человечьем понимании).
Итак у каждого бинарного образа можно вычислить несколько признаков, не зависящих от его поворота или размера, например число эллера, экцентрисетет и ориентация.
Как уже было сказано где-то в начале этой доки, можно собрать таблицу штук 8ми инвариантных признаков и распознавать образы исходя только из этих данных, однако мы пойдем другим путем.
Из всего множества инвариантных числе мы вычислим только одну ориентацию, для этого используем алгоритмы, похожие на MATLABовские (возможно они там и используются).
Далее идет цитата материалов описывающи модули работы с изображениями МАТЛАБА(откудавзят, указано в ссылках)
Однако описание неточно - как видно при вычислении С используется некое Uxy, которое не было введено ранее, в программе ест-но Uxy вычисляется коректно.
При вычислении ряда морфометрических признаков используются понятия механики твердого тела. В частности, это относится к длинам осей инерции объекта. Направления в теле, совпадающие с полуосями эллипсоида инерции, называют главными осями инерции. Для нахождения главных осей инерции, лежащих в плоскости объекта, в функции imfeature используются следующие соотношения [1, 2, 3].
Пусть N - количество пикселей, относящихся к объекту. Все множество пикселей р(х, у), относящихся к объекту, обозначим Q. Тогда координаты центра масс объекта вычисляются как
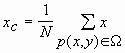 ,
, 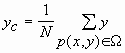
Вычислим несколько вспомогательных величин:
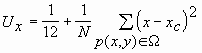 ;
;
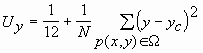 ;
;
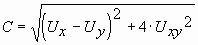 .
.
Тогда длины максимальной 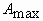 и минимальной
и минимальной 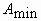 осей инерции вычисляются как:
осей инерции вычисляются как:
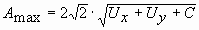 ;
;
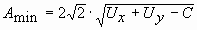 .
.
Длины главных осей инерции используются для вычисления эксцентриситета и ориентации объекта.
Эксцентриситет определяется с помощью соотношения
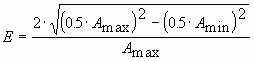 .
.
Ориентация определяется как угол в градусах между максимальной осью
инерции и осью X. Если 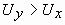 , то ориентация О вычисляется с помощью
формулы
, то ориентация О вычисляется с помощью
формулы
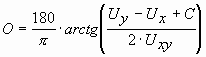 ,
,
в противном случае О вычисляется как
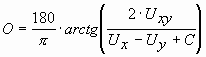 .
.
Поворот образа, повтороное выхватывание
Итак, найдена ориентация изображения, которая уникальная для каждого образа.
Сделано это для того, что бы теперь образ можно было повернуть относительно центра масс, так что бы его ориентация была паралельна оси Х. Собственно этот прием и дает инвариантность относительно начального поворота.
Ну и конечно некотороя демонстрация работы алгоритма вычисления ориентации и поворота бинарного образа.
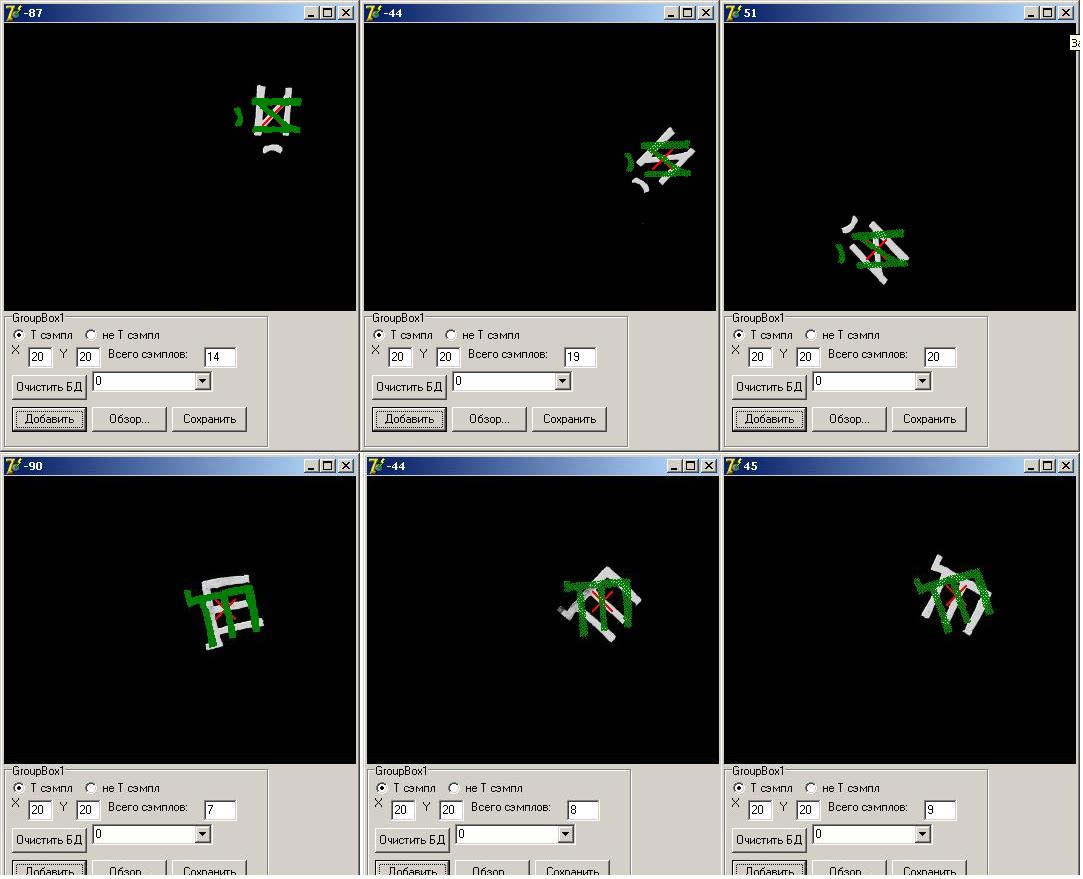
Выше белые буквы - это то, что видит камера, без всяких фильтров( только небольшая игра яркости и контраста). Красный крестик обозначает центр масс, вычесленный по формулам выше. Зеленые буквы, повернутые после вычисления ориентации по формулам выше. В процессе написания программы на этом этапе у мене еще не была отлажена сегментация, поэтому задача распознавания немного облегчена - на экране присутствует заведомо один образ, дальше будет сложнее
И еще одина картинка:
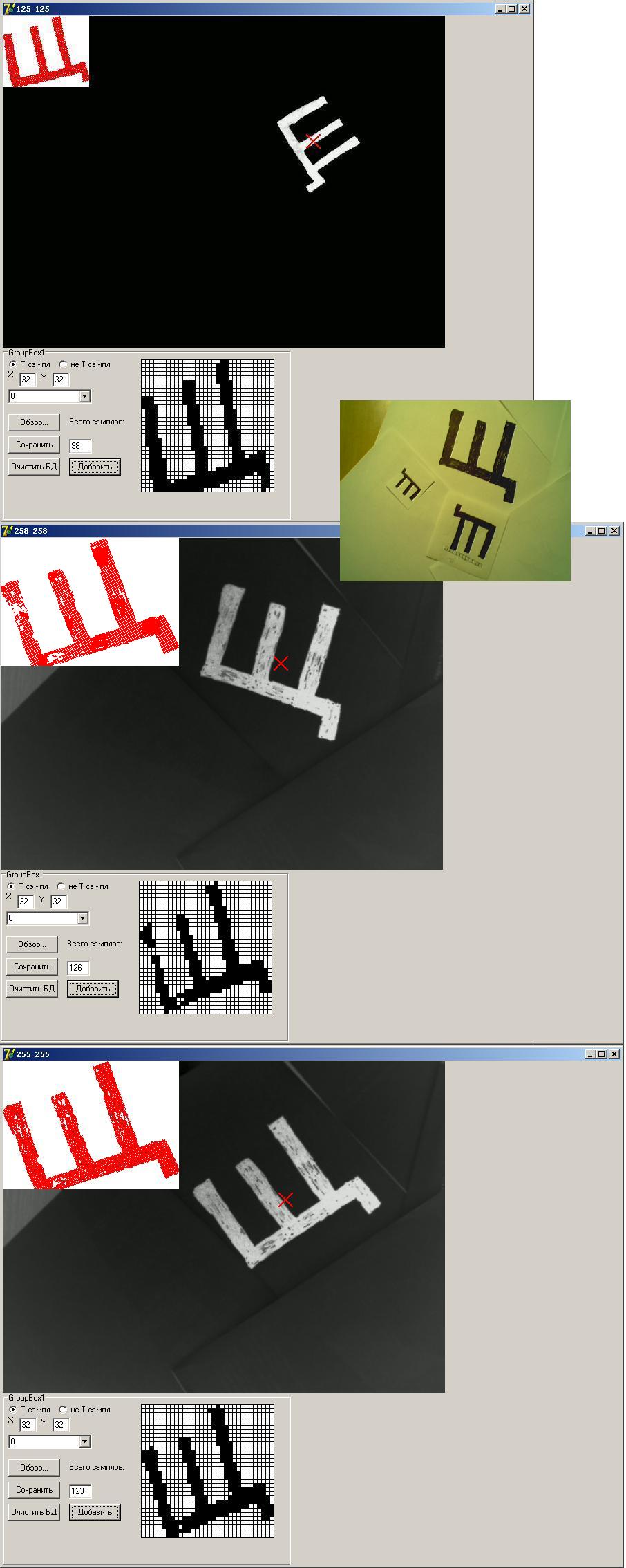
Внимательный читатель заметил бы, что ориентация это же не вектор, а только прямая! т.е образ можно повернуть и налево и направо. (ты невнимательный, раз об этом не задумался :-) На самом деле это даже и не проблема, во первых можно обучать нейросеть на двух примерах образа - положенного поворотом направо и поворотом налево. Это невполне коректно, но на простых вещах работает без потери качества. Во-вторых можно создать дополнительный тип для каждого образа - там он будет лежать развернутый в обратную сторону. В своей программе я использовал эти приемы через раз.
Сжатие образа в матрицу заданного размера
Как уже заметно из картинок выше, в оболочке программы появилась некая бинарная матрица, в которую ужимается каждый отдельно сегментированный образ. Размер матрицы задается по нуждам - т.е если нужна больша детализация, то лучше использовать матрицы большего размера, нежели в моей текущей версии программы. Это даст дополнительные вычисления на стадии распознавания, но по идее и повысит качество процесса. Однако важно понимать, что малое разрешение распознаваемой матрицы позвалаяет исправить некоторые возможные ошибки при повороте изображения(вычисления ориентации образа), т.к незначительное отклонение в 5 градусов, не будет заметно после сжатия образа.
На практике такие ошибки обязательно будут проскакивать, когда какую-то часть образа закроет помеха или блик - центр масс смещается, ориентация возможно тоже - поворот будет не вполне коректен. Если разговор пошел про блики, то надо уже накручивать оптику, и ставить возможные источники противоосвещения, но здесь важно понимать, что в реальных условиях при распознавании, образ никогда не будет виден камерой как должен быть на 100%. Т.е в движении хотя бы одна точка образа будет гарантировано переврана камерой , поэтому чем меньше распознаваемая матрица (т.е чем грубее ужимание до ее размеров) тем больше возможных ошибок будет незамечено, но тем меньше уровень возможной детализации.
Собственно, здеся я старался объяснить, что для каждой задачки размер матрицы надо выбирать соотетствующий. И не всегда чем больше тем лучше
Я работал с двумя размерами: 32х32 и 16х16, последний размер, для распознавания образов, примеры которых можно видеть на картинках мне понравился больше.
Распознавание образа нейросетью
А почему именно нейросетью?
Ответов не много: 1) научный руководитель в дипломной задаче указал мне их использовать. 2) просто хотелось познакомится с нейроструктурами.
Знающий человек может возразить, что при такой бинарной предобработке данных нейросеть здесь ни к селу ни к городу. Ну да.. может быть, однако приведу кое какие факты, замеченные при использовании алгоритма.
Изначально для проверки преобработки, и всех описанных выше алгоритмов, в качестве метода распознавания был воплощен алгоритм процентного сравнения с эталонами. Т.е изначально программа фотограффировала и предобрабатвала те ме же алгоритмами некие учебные образы, после чего, когда требовалось распознавать что-то новое, она это новое опять же таки предобрабатывала до матрицы заданного размера, и затем эту матрицу сравнивала со всем запомненными матрицами. Вообщем-то простой алгоритм, который исправно работал, посему я его осатвил в программе, а что бы использовать надо только раскоментировать некоторые куски.
Структура выбранной мною сети довольно стандартна:
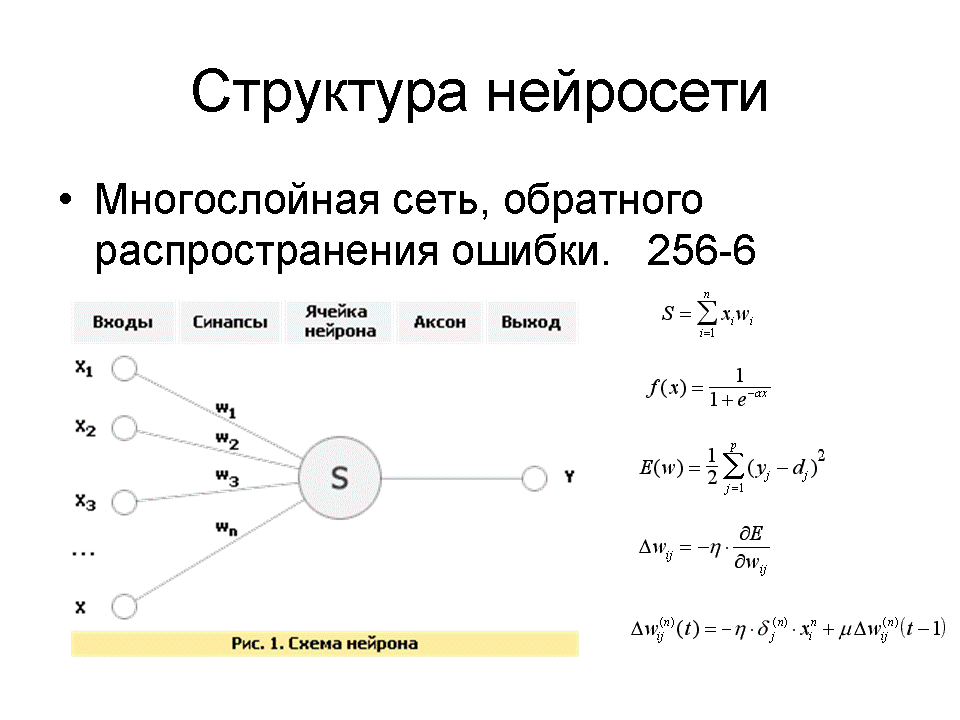
Многослойная нейросеть обратного распространения ошибки, занимается тем же, что и процентный алгоритм сравнения матрицы, однако за счет своей нелинейной структуры распознает она на 10-30% лучше тупово поточечьного сравнения двух матриц.
Для желающих познакомится с нейросетями поближе - в разделе ссылок есть пара url.
Для людей представляющих(или просто не желающих знакомится) скажу, что использовал бесплатные модули NeuralBase (из статьи нейросеть за 5 минут (см сыслки)). Модули мне очень понравились, довольно просты в использовании, можно вообще не знать что такое нейросети, используя их, но это и не очень интересно.
Раз уж я захотел познакомиться с сетями, то не смог удеражаться не поэксперементировав с их структурой. Мною были созданы две сеточки - одна 256-6, вторая 256-40-6. Первый слой в 256 нейронов это вход матрицы 16х16, последний слой это вход - распознаем к примеру 6 букв.
На практике, нейросеть из трех слоев (с некой внутренней обработкой - в 40 нейронов) обучалась с трудом, постоянно ловя локальные минимумы (вывод сделан из поведения среднеквадратичной ошибки, выведенной в реальном вермени при обучении). Качество же распознавания визуально не возрасло.
Посему я решил, что лишние вычисления бесмысленны и остановился на простой структуре в 256-Х(где Х - число заученных образов), которая обучается довольно непродолжительное время, ведет себя стабильно и показывает хорошие результаты.
За результат распознавания был взят выход нейрона, больший 1-K, причем ни один из других выходов не может быть больше K. В моей задаче К берется равное 0.2, т.е можно провести некоторую аналогию с процентным сравнением (за истину берется больше 80% совпадений), с той лишь разницей, что нейросеть "сравнивает" нелинейно.
Пример распознавания образов
Итак, как и было обещано, данная статейка написана с упором в практическую часть, поэтому прехожу к примерам и собственно исходникам программы.
Для начала - где все это придумывалось и писалось:

Красное сверху, это самая дешевая USB камера, которая может давать разрешение 640х480 (не принципиально, но для стандарта) при 30 кадрах в секунду.
Обошлась в 600р, с гартитурой в подарок (микрофон с наушником - довольно удобно для Skype). К слову сказать, можно вязть камеру еще дешевле - до 300р. Однако использовать такие камеры в реальных мехатронных системах для реального распознавания - не дай бог.. если кому-нить будет интересен мой опыт общения с камерами - напишу отдельно.
Далее начинается самое интересно - можно увидеть алгоритм в деле, когда одновременно работает сегментация и распознавание:
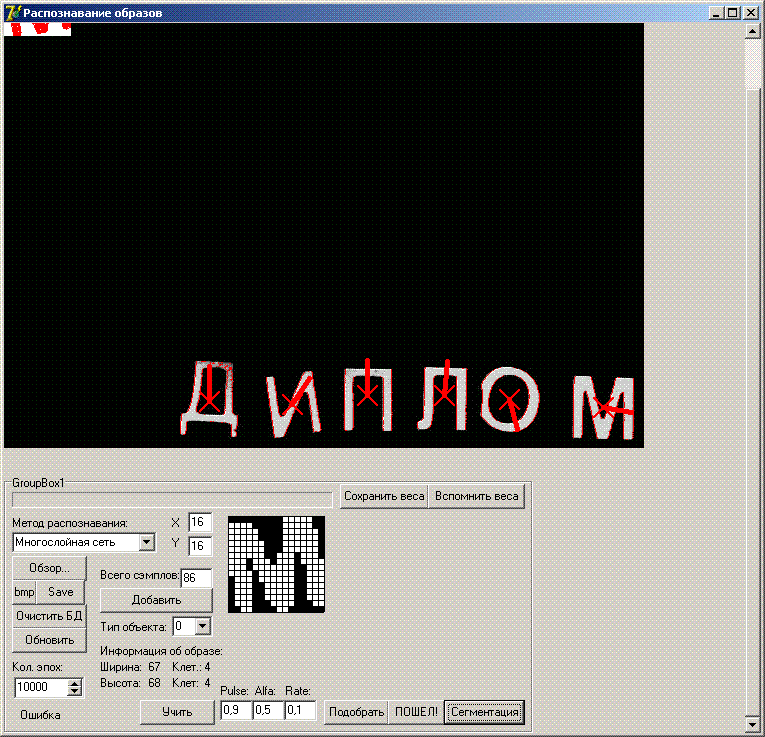
На рисунке выше - буквы распечатанны на бумаге, и положены на стол, над которым закреплена обычная USB камера. Красные крестики -центры масс каждого образа, красные линии - ориентация.
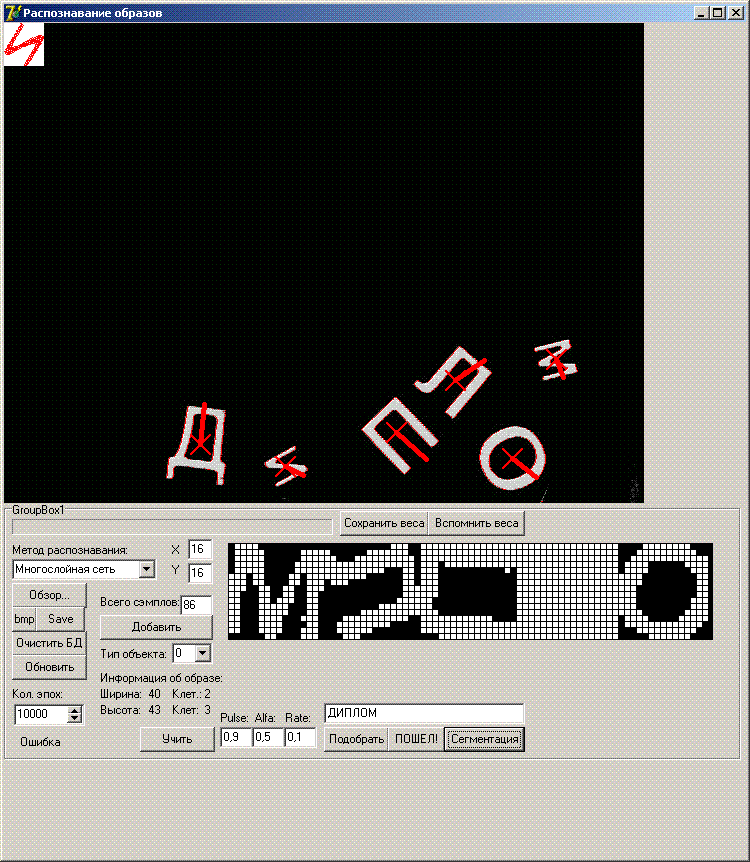
Кажется что задачка немного усложнилась, но для программы это не имеет значения - для нее все буквы, которы кажутся ровными для человека, повернуты неправильно, и она их крутит по своему как хочет.
Так же можно увидеть, что в оболочке программы появилось напечатанное в текстовом поле слово "Диплом" - это собственно результат распознаванияя - т.е программа фактически прочла образы слева на право.
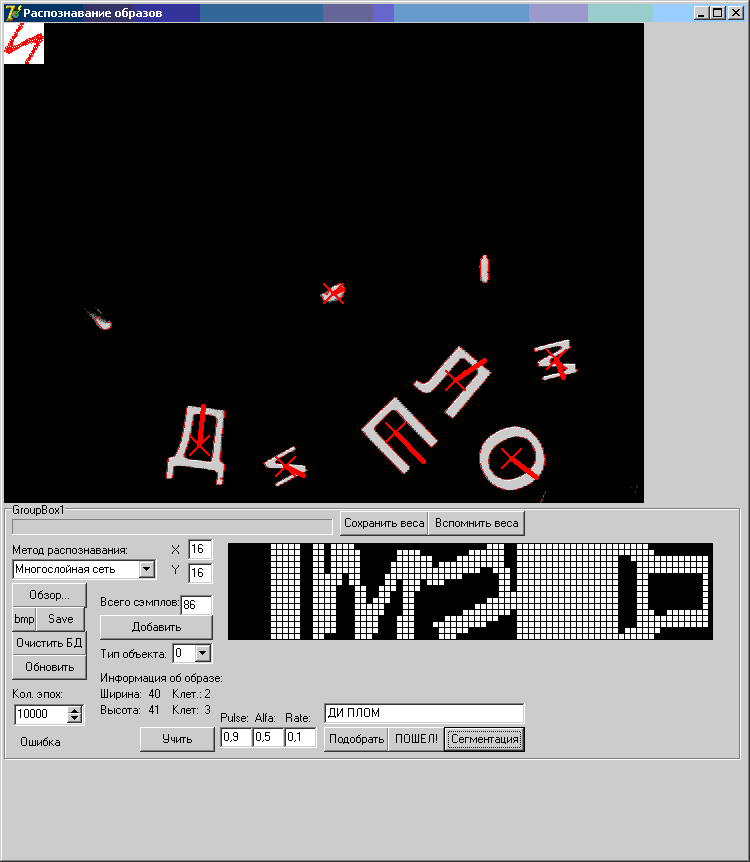
А здесь мы добавили инородного мусора: те куски, где не стоят красные крестики, обозначающие центр масс - вывалились на стадии сегментации, как не прошедшие фильтр по площади - слишком малы. Третий кусочек мусора вошел в модуль распознавания (после стандартной предобработки), но не был ей распознан - нейросеть его не признала.
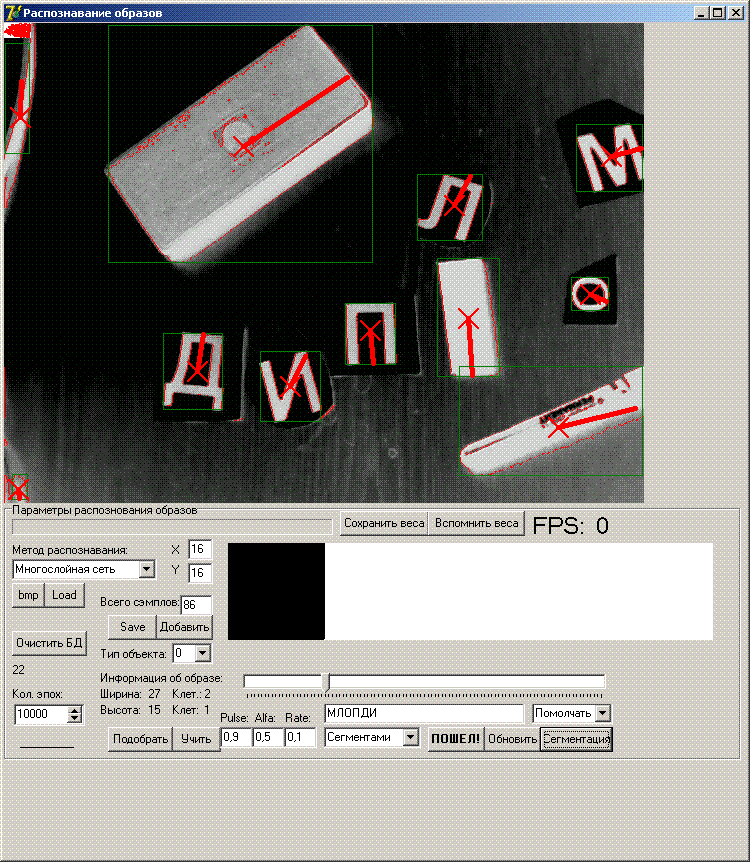
Ну и последняя картинка - можно убавить и яркость и контраст, изображение становится более реальным, вдобавок наложим побольше посторонних предметов. Сортировка букв слева на право отключена, потому что в этой задачке она вообще не требуется - робот не должен читать слова - его задача только лишь понимать что на экране в данный момент присутствуют такие-то символы, и раз так, то по программе он должен сделать то-то.
Здесь так же интересно заметить последовательность в которой программа вывела распознанные символы: "МЛОПДИ" собственно это последовательность сверху вниз, как и должно быть по проходу алгоритма сегментации.
На последнем изображении видно, что в оболочке программы появилась обривиатура FPS - программа может распознавать от 5 до 20 кадров в секунду в зависимости от сложности картинки. Текущая картинка распознается с FPS=15.
Программа и как ею пользоваться
Представленная версия программы создана для конкретного робота, поэтому в ней есть много лишнего, явно не нужного читателю. Более того из-за обилия кнопок и всяких окошек интуетивно не понятно, как использовать софт.
Посему выкладываю небольшую инструкцию.
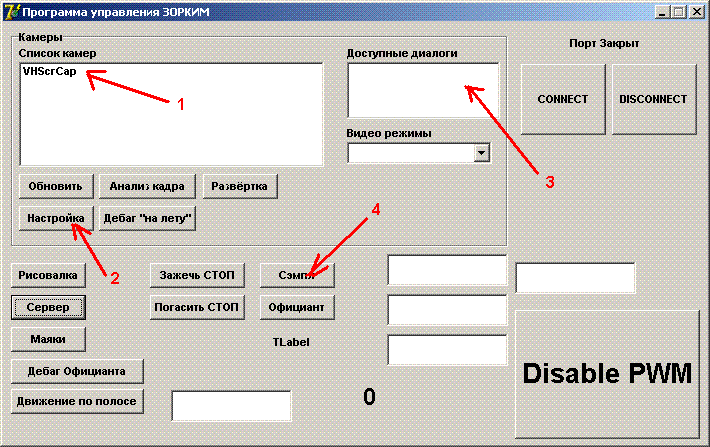
Итак в первом окне программы для начала надо выбрать активную камеру (1), затем нажать кнопку настройка и в диалоговом окне указать настройки камеры, поставить галки где нужно(2). В опции "функция" требуется выбрать "полигон-вперед".
Затем в диалоговых окнах камеры(3) (у разных камер может быть разное число диалогов и уж точно они выглядят по разному) надо выбрать параметры - число кадров в секунду, яркость, контрастность и т.п. Под конец, для вывода главного диалога программы надо нажать кнопку "сэмпл" (4 ).

На рисунке выше показан главный диалог программы распознавания образов.
Для начал нужно заготовить образы и обучить программу. Образы нужно предъявлять белые на черном(или поменять в проге) и по отдельности.
 Порядок действий при обучении должен быть следующий:
Порядок действий при обучении должен быть следующий:1. Из папки DATA стереть фаил config - в котором содержится информация о предыдущих разученных образах.
2. Далее запустить программу, настроить камеру, и открыть окно распознавания образов.
3. Нажать кнопку "обновить". (должна появиться чистая ЧБ картинка.
4. Указать тип образа, который должен быть добавлен.
5. Нажать кнопку "добавить". Повторить операцию(4 затем 5) обновления и добавления столько раз, сколько образов используется.
6. После того, как добавлены все образы нажать кнопку "Save" рядом с "добавить".
7. Закрыть программу, открыть в блокноте фаил config из папки DATA, убедиться, что данные для обучения получились коректными.
8. Запустить программу заного, открыть окно распознавания, ввести параметры обучения и работы нейросети.
9. Нажать кнопку "учить".
10. Наблюдать за обучением нейросети (2-20 минут, в зависимости от машины и сложности задачи).
11. После успешного обучения (ошибка меньше 0, а лучше 0.1) нажать кнопку "сохранить веса".
12. Закрыть программу.
Если все прошло успешно, то на этом этапе программа обучена на распознавание указанных образов и готова приступить к работе.
Что бы заставить программу работать надо:
1. Запустить программу, выбрать и настроить камеру, очень важно, что б настройки были идентичными как и при обучении.
2. Нажать кнопку сэмпл, открыть основное диалоговое окно распознавания
3. По надобности нажать кнопку обновить, после того как будет подготовлен объект перед камерой.
4. Нажать кнопку "сегментация". После чего должна быть выведена вся информация дебага на экран, и в фаилы
5. Если дебаг прошел нормально, все образы выделяются и распознавются, то можно нажать кнопку "Пошел" - это запустит паралельный процесс распознавания, но уже без визуальной информации, что бы не тратить на нее вермя.
Вообщем-то все. Если кому-то понравятся идеи, изложенные в этой статье, то думаю что в программе он тоже разберется - было бы желание, в любом случае можно воплотить этот алгоритм самому, или даже сделать его лучше.
Исходные тексты программы.
Еще раз повторюсь, что программа содержит много модулей, которые не относятся к распознаванию, посему небольшая памятка для тех, кто полезет в исходники.По части видео интересны только модули и функции в них:
unit UMain
Кое какая инициализация касательно камер
unit UPreview
модуль общения с камерами.
unit UCamTimers
модуль выствления таймеров камер
unit UGraphConfig
Модуль настройки камер.
unit UCharAnalyz
procedure TRobotRecognition.execute() - нить паралельного процесса распознавания
procedure NeuroCompute - вычисление результатов нейросетью
procedure segment - сегментация бинарного изображения
function get_parent - рекурсивный поиск родителей метки, для сегментации
function normalize - нормализация массива меток - сейчас может и не нужна
procedure reader - сортировка распознаного и чтение вслух
procedure ConvertBitmapToMonoChrome - бинаризация
procedure BitmapToIcon - сжатие в матрицу 16на16
function CompareIcons - процентное сравнение двух матриц
procedure AddSample - добавление примера для обучения
function TSampleRule - сравнение образа процентами или нейросетью
unit UAddSample
procedure imFeatures -предобработка образа, вычисление центра масс, ориентации поворот
Материалы, которые мне помогли, когда я это делал(или только выбирал каким путем пойти) :
Раздел про алгоритмы распознавания образов в целом
Захват видео в Windows
Демо исходники с которых я начинал разбираться как достать видео. В моей полной программе они модифицированны для работы с несколькими видео камерами.Бинаризация
Сегментация
Поиск объектов и вычисление их признаков
Распознавание образов нейросетью
Картинки с синми роботом взяты из классной книжки "О чем размышляют роботы" Жана Пьера Пети, издательство МИР 1987г. Рекомендую.
Скачать
Исходные коды моей программы
Для начала упомяну, что в программе используются модули разных авторов. Все разрешают использовать их коды в некомерческих или образовательных целях, за более подрбной информацией необходимо пробежаться по сайтам источников(я вроде бы все указал).
Мои модули можно так же использовать бесплатно, в некомерческих или образовательных целях, публиковать в других местах можно только с согласия автора, т.е меня.
Программа поставляется как есть - она может не запуститься, навредить, навредить сильно - за все это я ответственности не несу, компилируйте и запускайте на свой страх и риск.
Теперь о хорошем - скачать программу можно здесь 1.6Mb:

главный модуль программы PZorkiy - по имени нашего робота.
Модифицированный модуль работы с нейросетями для delphi (я юзал под delphi 7):
Да простят меня авторы из BaseGroup Labs - выложил модули нейросеток, которые я юзал на момент написания этой приблуды, исходники я немного модифицировал - сделал доступ извне к свойству веса нейрона, для сохранения и загрузки в файлы в случае выхода из программы. Наверное где-то что-то было реализовано по человечески и это была лишняя и глупая работа, но на тот момент я ничего не увидел. "тырить и перекладывать" исходники это конечно плохо, но я не уверен что, содержимое оффициального сайта будет совместимо с моей приблудой для распознавания(я сделал глобальными переменные весов сети, чтобы можно было их сохранять в файл и загружать обратно).
Собственно вот и все. Если кто-то надумает продолжить тему, вопросы и пожелания на mega16@mail.ru
P.S. Так, настало время написать по поводу дипломов, "сделай за меня", "помоги сдать" и т.п. Достали.
Господа студенты! Я прожил совсем не многим больше вашего, сам защитил диплом 5 лет назад - но уже с уверенностью могу сказать, что если вы нихрена не знаете, "корочка" вам в жизни не поможет. Дипломчик на халяву может проскочить легко, в современных российских(большую часть стран СНГ туда же) вузах все деградировало очень серьезно. Кстати, давайте задумаемся почему? Да потому, что никому не нужна эта самая честная защита, не нужны инженеры, не нужна промышленность, не нужна наука. Как следствие - даже если вы будете реально учиться, получите настоящую инженерную специальность, то в будущем у вас ждут значительные проблемы с карьерой. Работу вы конечно найдете, но общая невостребованность понятным образом скажется на окладе - вы сможете получать среднюю зарплату, "как все", но без перспектив. (есть конечно вариант "уехать на запад", но если вы просите помощи с такой плевой програмкой, то видимо не потяните, я не потянул)
Но это про тех, кто реально учился и что-то понимает. Есть еще довольно значительная группа людей, которая вроде как училась в вузе (вероятно программированию) но не способна разобраться и запустить готовую программу. Товарищи, я понимаю, что у вас защита через неделю(месяц, пол года) и вы кроме этого нихрена не видите вокруг, но если заглянуть в будущее - дипломчик вам хорошо не сделает. Он дает некоторое преимущество в трудоустройстве, но это только мнимое преимущество. Если вы собрались трудиться там, где формальное требование наличия высшего образования невозможно обойти своими навыками, талантами, то вас ожидает скотская работа, на которой не нужны знания, там не будет перспектив, драйва, достатка - скотская работа, скотская жизнь. Как я могу вам в этом помочь, да еще получить за это деньги?
В случае использования высшего образования как средства вренного "откоса" от армии, увы и тут вы ошиблись. До тех пор, пока в стране процветает коррупция, беззаконие, пока в армии этой страны служить непристижно - будут существовать варианты обойти все это. Достаточно забить в поиске "отсрочка от армии" или подобные запросы - вы увидите кучу адвокатских контор, которые помогут решить ваши проблемы за сумму явно несоизмеримую с убийством 5ти лет жизни ради синей "корочки". Так что и тут вы ошиблись.
Суммы, которые вы называете в качестве благодарности - смешны. Где логика, господа? Если я после этой программульки не смог устроить свою жизнь, в том числе и материальную, не смог найти себе интересное занятие, чтобы не отвлекаться на ерудну - нахрена вам повторять мой отрицательный опыт и сдавать в качестве диплома такую же? Время бы остановится, подумать "да что ж я блин делаю-то?", но это не ваш случай у вас же скоро защита... она конечно "важнее".
Скажу честно, цель написания данной статейки - поделиться идеей и ее реализацией, но мысли "подзаработать" у меня на момент написания были(да да, я ж был такой же студент как и вы!), но это было тогда - прошло всего лишь 5 лет и я однозначно понял, что это чушь и пустая трата времени, а живем-то один раз!
Короче, халявщики - идите лесом. Тем, кто реально хочет поковырять это направление, я с радостью, бесплатно подскажу что в моей программе несоврешенно, как бы я все это сделал сейчас, что можно доделать, чтобы повысить качество и т.п.
Всегда Ваш
Письменный Николай, 2007 г.
Другие мои схемки и решения:DC-DC преобразователь и фильтрация питания
Ультразвуковой дальномер