|
Данную статью я посвящаю также распознаванию образов нейронными сетями, но она является своего рода продолжением или, если хотите, расширением статьи по распознаванию образов Письменного Николая, потому что очень много материала перекликается и используется из его публикации. Так вот, так случилось, что ко мне неожиданно подкралось время написания выпускной дипломной работы в универе, и скрепя сердце я начал искать материалы по теме распознавания образов. Задача немного облегчилась, когда мой научный руководитель уточнил тему диплома, звучала она так: «Распознавание образов с помощью нейронных сетей методом обратного распространения ошибки». И вот я после тучи обрушившейся на меня информации, нашел публикацию Николая. Изучив это все хорошенько, я принялся за написание диплома.
Конечно, получившаяся программа имеет серьезные отличия. Во-первых, у меня, распознавать образы можно, используя только один метод - «обратного распространения ошибки», в то время как у Николая их было несколько. Во-вторых, у меня программа не для работы с роботом, а для запуска на обычном персональном компьютере (ПК). В третьих, для простоты я сделал так, что распознаваться может только один образ(в моем случае это тоже буквы) в текущий момент времени, а не много и по очереди:) Ну, это из основного. А дальше по ходу статьи я сообщу еще несколько отличий, которые были хоть и не столь масштабны, но все таки имеют достаточное значение, чтобы упомянуть их.
Программа использует тот же метод сегментации изображения и, соответственно те же Паскалевские классы QPixels. Но моя задача заключалась в том, чтобы, ко всему прочему, основной код диплома был написан на C++. И тогда я принял решение писать это все на Borland C++ Builder 6.0 потому что (насколько я помню) только в билдере возможно компилировать одновременно Си-шный и Паскалевский код. Не буду описывать здесь математическую базу нейронных сетей, процесса сегментации и прочего(обо всем этом Николай и так уже подробно написал), а опишу только вкратце структуру проги и приложу несколько скринов.
Так как класс QPixels написан на паскале, то надо сделать импорт этого *.pas-овского файла в Борландовский проект. Тогда сам Билдер сгенерирует соответствующие *.hpp файлы с описанием этого класса уже на C++ и тогда эти заголовочные файлы уже можно подключать в коде и юзать спокойно этот класс. Как видите – вроде не очень сложно. Дальше интересней…
Я хотел также, чтобы в моей проге была доступна опция взятия картинки с веб-камеры. Для этого я использовал библиотеку OpenCV, которая предоставляет необходимую функциональность. Кстати сказать, библиотека эта написана на C/C++, так что это даже оказалось очень кстати. НО, а как же распознавание? Тут не все так быстро. Если вы помните, нейронная сеть свой процесс «отгадывания» символов строит на том, чему она до этого обучилась. А вся штука в том, что обучается она на, так называемом, обучающем множестве. Так вот это множество как раз и необходимо создать. По сути, структура может варьироваться в зависимости от поставленных задач, но конкретно в моем случае я сделал так. Чтобы добиться относительной шрифтонезависимости при распознавании, я нарисовал по 30 русских прописных (печатных то бишь) букв двадцатью разными шрифтами. Почему 30 букв, а не 33? А потому что я брал только буквы, написанные цельным символом, т.е. я выкинул буквы Й,Ё и букву Ы. Картинки я сделал 32x32 пикселя. В программу я также добавил функционал для «монохромизации» любой поступающей картинки – делаю ее монохромной. Таким образом, после сегментации каждой из таких букв, я получал строку длиной 1024 символа, состоящую из нулей и единиц (само собой, что белый цвет пикселя означал 0, черный 1). Строк получилось 600. Все это я запихал в текстовый файл, который и превратился в обучающее множество. Выглядело это так:
|
|
| Дальше надо было сделать собственно распознавание. В интернете я нашел очень интересную библиотеку по нейронным сетям, заточенную на C++. Называется она FANN (Fast Artificial Neural Network Library). Её и использовал. Нейросеть я сделал со следующей структурой: всего 4 слоя, первый – состоит из 1024 элементов(картинка 32x32 пикселя), потом два, так называемых, «скрытых слоя» по 512 элементов, и заключительный слой в 30 элементов – по количеству возможных распознанных букв. Такая структура сети ничем конкретным не обусловлена. Для тех, кто не читал литературу по нейронным сетям, я скажу, что на данный момент времени ученые пока не смогли придумать алгоритмы(да и теоретическую базу вообще), которые однозначно бы определяли сколько слоев должна содержать сеть, чтобы распознать то-то и то-то, и сколько элементов должно при этом быть в каждом слое. Ну, а для тех, кто читал об этом – я не сказал ничего нового. Я пришел к таким результатам исключительно опытным путем, потому что на данном обучающем множестве и с данной структурой нейросети – распознавание образов проходило наилучшим образом, да и время обучения сети было достаточно приемлемое, порядка 13-16 минут. Плюс к этому, сеть практически никогда не ловит локальных минимумов, что также говорит в защиту выбранной мной структуры.Первый слой нейросети – это, собственно, та картинка, которую нам надо распознать. Каждая строка файла обучающего множества – это эталонная буква алфавита. Мы много-много раз прогоняем в режиме обучения нашу сеть, и она постепенно запоминает все эти 30 эталонных букв для каждого из 20 алфавитов, а потом, благодаря своей структуре она в состоянии распознать не только эти заученные буквы, но и буквы с небольшими дефектами. А так оно работало: |
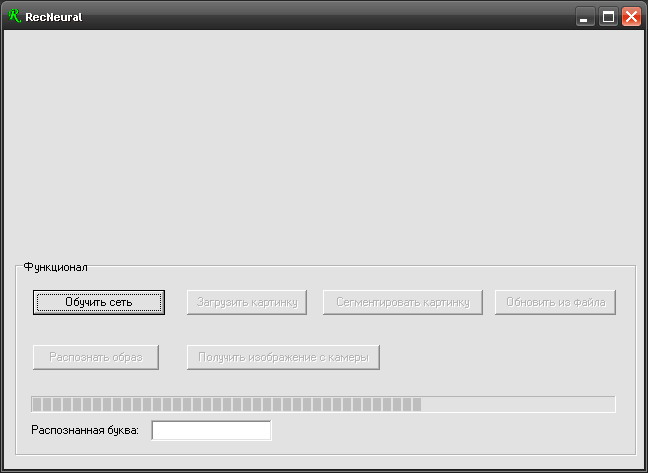
1) Обучаем нейросеть:
|
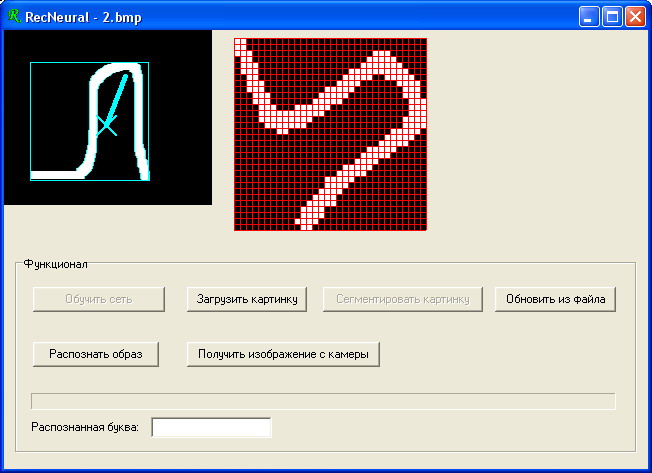
2) Загружаем картинку из файла и сегментируем ее:
|
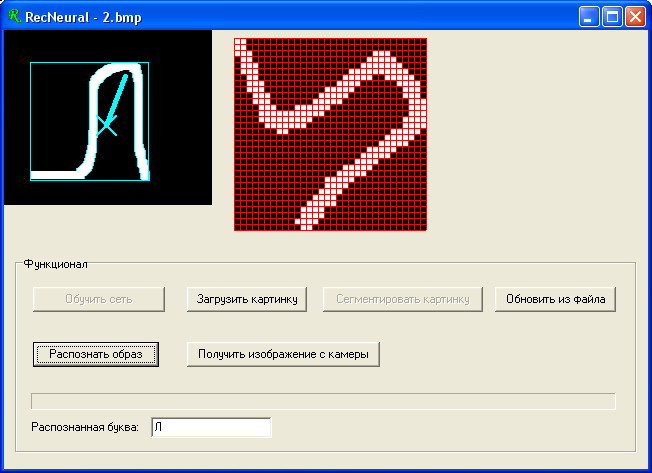
3) Распознаем букву (результат внизу скриншота):
|
Или вот еще скрин распознанной буквы. Картинку получаем с веб-камеры:
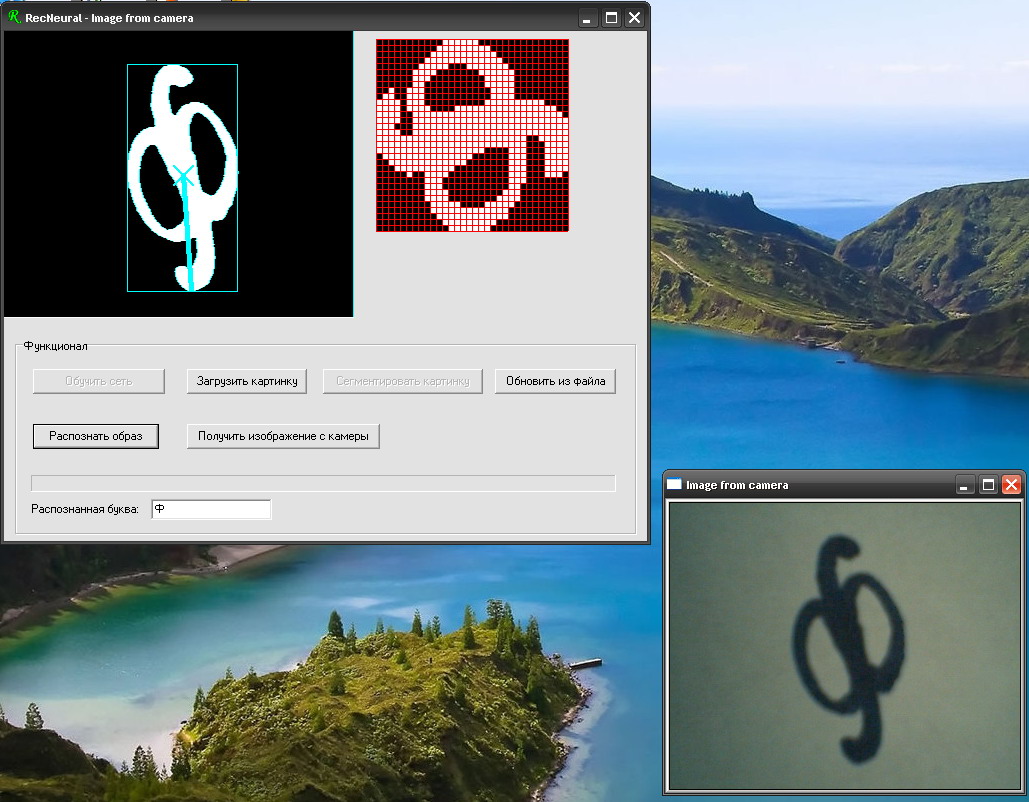
|
| В общем, если подвести некий логический итог этой статьи, то я скажу, что диплом я успел сделать вовремя. Ну а если серьезно, то – эта программа специально создавалась, чтобы показать всю красоту и мощь нейронных сетей. Так как аппарат нейронных сетей наиболее подходит для классификации образов, то именно они и были использованы, хотя не спорю, сторонники других методов могут привести массу контраргументов не в пользу сетей. Но тут уж, как говорится, дело вкуса, скорости работы метода, да и вообще, все зависит от поставленных перед человеком задач. Конечно же, как и в реальной жизни, здесь не все идеально. Есть свои минусы и плюсы. Минусы, например, в том, что если кусок изображения накроет блик, то сдвигается и центр масс и ориентация – алгоритм сегментации(и, как следствие, дальнейшее распознавание) не сработает. Также не допустимы разрывы в объекте. Объект в данном случае – это буква на картинке. Но есть и свои плюсы. Например, то, что реализованная нейронная сеть является относительно шрифтонезависимой, поскольку обучена на 20-ти наиболее распостраненных шрифтах, поддерживающих русский язык. А также то, что мелкие ошибки поворота, неточности бинаризации и т.п будут естественным образом сглаживаться на стадии ужимания в матрицу-иконку. Ну, и само собой, принципы, реализованные в данной программе могут быть использованы в любых задачах, связанных с классификацией, например, при распознавании вагонных или автомобильных номеров |